
In this post I will present some changes I have made to my SitecoreSuggest integration between Sitecore XM and Open AI. These changes will allow the generation of “context-aware” suggestions within Sitecore using ChatGPT (like keywords based on existing content). I am also going to explain how tokenization is done by the GPT models. The reason I have combined these two seemingly unrelated topics is because the counting of tokens was an obstacle which I had to overcome to be able support context-aware suggestions – and it turned out to be a quite interesting one.
Please notice that this post is in many ways a follow up on my previous post in which I introduced my SitecoreSuggest integration. So, if you have not read that post, it might be a good starting point before diving into the this post.
You can download SitecoreSuggest from my GitHub. Currently the changes present in this post is in the develop branch, but once I am comfortable with them working perfect, I will merge them into the main branch and they will become version 0.2.
What is context-aware suggestions?
In my initial version of SitecoreSuggest I primarily used the completions endpoint from Open AI. This endpoint is simple: You send a prompt containing all the “instructions” needed for the GPT model to create a response and send it back.
This means that we need to use a “self-contained” prompt like “Write something about the planet Saturn” that does not require any additional information.
To generate these kind of responses SitecoreSuggest uses one of the “instruction-following” models like gpt-3.5-turbo-instruct – available via the completions endpoint. These models that optimized to take a single instruction as a prompt and generate an answer.
However, in Sitecore we of cause always work in a context of a page. This becomes apparent when we try to create e.g, SEO keywords and SEO descriptions for an existing page. What I would like SitecoreSuggest to support is prompts like: “Write about 20 keywords separated by commas”, and to be able to respond like it already “knew” the content of the page. This is what I call a context-aware suggestion.
I have been experimenting with different approaches to this, and in this post, I will present a working solution: The context is here is the current page including all rendering datasources on the current langauge, and I will refer to the complete list of fields on the page and rendering datasources as the context fields.
The benefit of context-aware suggestions
To understand the benefit of context-aware suggestion, we will start by looking at the SitecoreSuggest from an editor’s point of view. Let’s say we have created a page about the planet Saturn.
On the page we have inserted a rendering called TextModule which has been added to the page in the main placeholder. The rendering displays a title and a text which it gets from this datasource:
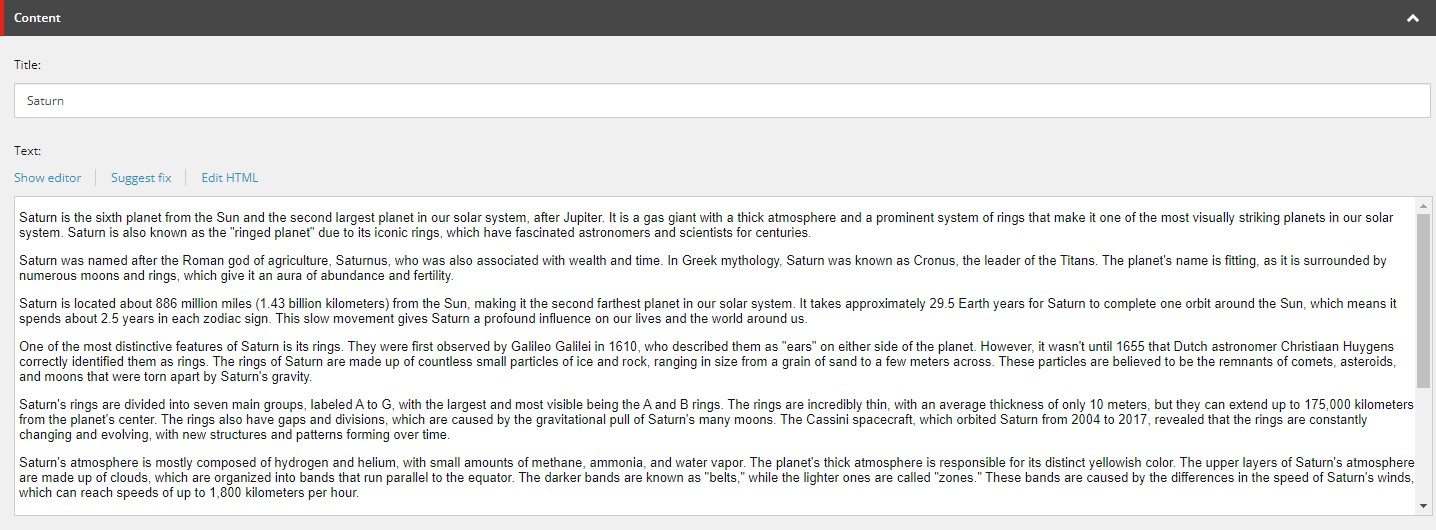
However on the page we have two fields for SEO metadata, a field for keywords and one for a description:

So, what we can do is to open SitecoreSuggest, enter the prompt “Write about 20 keywords separated by commas” and select to Use chat model and include context. As you can see, SitecoreSuggest will now respond with a list of “context-aware” keywords based on the context in which we ask for keywords:
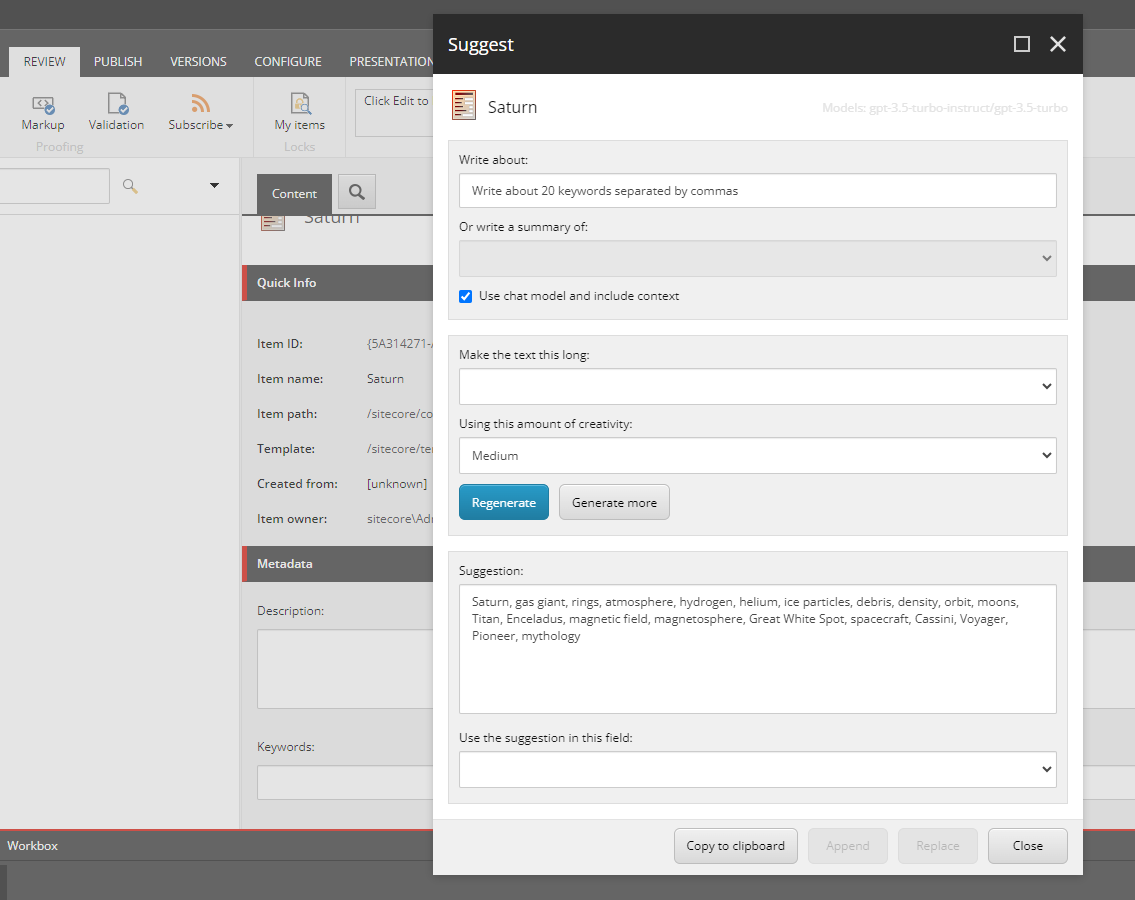
What happens behind the scene is actually quite simple: By selecting Use chat model and include context, SitecoreSuggest uses the chat endpoint, and the request sent to the ChatGPT model contains all the context fields as system messages:
{
"messages":[
{
"role":"system",
"content":"Context: Saturn"
},
{
"role":"system",
"content":"Context: Saturn is the sixth planet from the Sun and the second largest planet in our solar system, after Jupiter. It is named after the Roman god of agriculture and wealth, Saturn. It is a gas giant with a diameter of about 116,000 kilometers, making it almost 10 times larger than Earth. It is also known for its distinctive rings, which are made up of billions of tiny ice particles and debris [...]"
},
{
"role":"user",
"content":"Write 20 keywords separated with commas"
}
],
"n":1,
"stop":null,
"temperature":0.5,
"model":"gpt-3.5-turbo"
}
I have cut the long text in line 9, but the actual request SitecoreSuggest sends includes the Title and entire Text fields from the datasource (after removing the HTML tags in the Text field). If content was added in the Description and Keywords fields on the page these fields would have been included as well, but since they are empty the fields are skipped.
You will notice that the context fields are sent using the prefix “Context” and with the role system. As we saw in my previous post, the chat endpoint is stateless, but allow us to send a chat history, so what we are doing is putting the model on the “right track” by adding the context fields a system messages, which can be used for giving the model the needed context in which to reply.
I was really happy about this implementation because it allows be to generate keywords and descriptions based on the existing content, and in many way this post could have ended here, but there was a catch: On pages with about 4-5 times the amount of context fields I ran into problems with the gpt-3.5-turbo model, and on pages with non-English text this happened even with less content.
Token limits and counting tokens
The problems are that when we start to include context fields – especially rich text fields, we will need to account for the token limitations of the Open AI models. In the case above the context fields consists of a rather long text about Saturn which consists for 951 tokens, together with a title consisting of 3 tokens and a of 8 tokens – in total sending 962 tokens to the model.
The model I am using (gpt-3.5-turbo) has a token limit of 4097 tokens which include both the messages we send to the model as well as the models response. So in the example above we have 3135 tokens left for the response which is more than enough. But if we had more than 4097 tokens of context fields, we would have a problem.
So, if we e.g., add 5 TextModule renderings with the same amount to text we will get an error because we would be sending close to 5000 tokens to the model. Actually, already at 4097 tokens we have problems, because we also need to “make room” for the response which is also part of the token limit.
With the gpt-3.5-turbo model, we probably should not include more that about 3000 tokens of context fields. This will leave about 1000 tokens for the response which in English is about 750 words.
To be able to do this, we need to be able to count the tokens of each context field we add to the request before we send the request. When we reach the limit of 3000 tokens, we need to stop adding more context fields to avoid errors and leave room for the model’s response. But how do we go about counting the tokens before sending the request?
In general, there is a rule-of-thumb of 0.75 words per token in the English languages on average – this means that some text will contain more tokens, and some less. So, in theory we could simply count the words and divide the word count with 0.75. This would allow us to add 2250 words of context. However, this rule of thumb is not good enough because it only applies to English texts. Non-English texts have way fewer words per token: In Danish it is not uncommon that each word is split into 3 tokens on average (or 0.33 words per token). This means that if we rely on the rule-of-thumb we would almost certainly run into problems with non-English languages because we would add to many tokens to the request.
The best approach would of cause be that Open AI exposed a token-counting endpoint, but right now such an endpoint does not exist. Luckily there is NuGet packages our there that we can use to get an accurate token count for a specific text locally. But to be able to use these packages efficiently, we need to understand a bit about the how the GPT tokenizer works.
How does GPTs tokenizer works
While there is not OpenAI endpoint to which we can send a text and get the number of tokens back, there is a page where we can input a text and get it tokenized using the GPT-3.5 tokenizer:
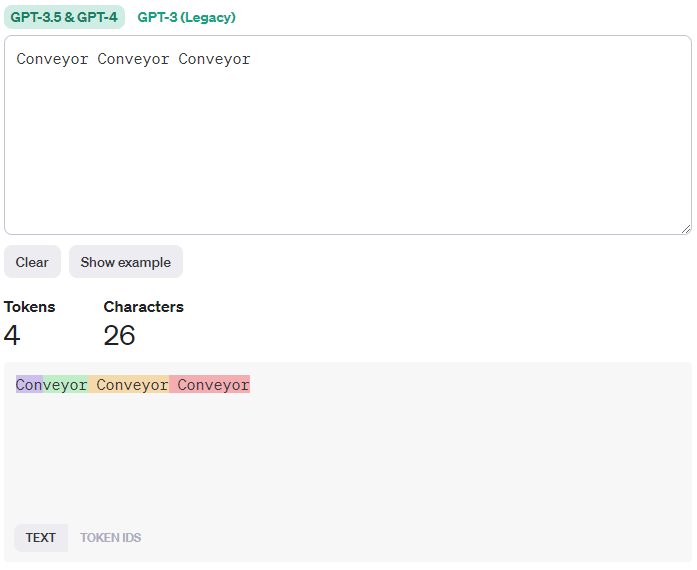
Above I have entered the rather meaningless text “Conveyor Conveyor Conveyor”. This text is being tokenized into 4 tokens. We can inspect the token IDs and see that they are [1128, 69969, 100255, 100255].
This means that the two last word “Conveyor” represents a single token with the ID 100255 whereas the first “Conveyour” is split into two tokens (1128 and 69969).
What is important to notice is that each token have a unique ID. The Open AI tokenizer is not just some fancy regular expression we can replicate in our code – it actually uses a vocabulary of tokens where it maps each token to a ID. Also worth noticing is that the vocabulary must include some “metadata” to allow the tokenizer to tokenize the first word in a text in a special manner.
So, to do the tokenization locally, we need a vocabulary, and the version I use can be found in this repo by Xenova. It has been comes from the open source version of the tiktoken tokenizer made public by OpenAI so it should be okay to use.
The vocabulary consists for multiple files, and while I am not 100% into the finer details of the different files, we need at least two files: merges.txt and vocab.json.
The merges.txt file is used for tokenization and describes rules for merging tokens starting from single character tokens. The list of rules is run repeatedly merging characters into clusters of characters and then potentially clusters into words. When the file is run without any more merges being possible the tokenization is complete. To understand this, let us look at the last rule in the file:
ĠCon veyor
The Ġ indicates a space, and this rule allow the merging of the two tokens ĠCon and veyor produced by earlier runs. This means that my text is merged into smaller clusters of characters until it consists of these tokens Con|veyour|ĠCon|veyour|ĠCon|veyour. The final rule allows the third and fourth as well as the fifth and sixth tokens to be merged to form these four tokens: Con|veyour|ĠConveyour|ĠConveyour. If you want to dive into the exact process of merging I have written a GTP compatible tokenizer that can output each merging step which you can download from my GitHub.
Next the tokens are assigned IDs using the vocab.json vocabulary file containing the about 100.000 tokens. In this file we find the following these entries:
"Con": 1128,
"veyor": 69969,
"ĠConveyor": 100255
This gives us the tokenization [1128, 69969, 100255, 100255] matching the one produced by Open AI.
On a side note, please note that while the order of tokens in the vocab.json vocabulary file does not matter, the order of the merging rules in merges.txt are important because the rules are applied in iterations where the first matching rule will be applied (see my tokenizer example). If we take e.g., these two list of the same merging rules below but swap the last rule, notice how they will produce different tokenization of the word “intone”. This is because in the fourth iteration running on the tokens in|to|ne different rules will take precedence (either in to or to ne):
| Merge rules 1 | Tokenization 1 |
| i n t o n e in to to ne | i|n|t|o|n|e → |
| Merge rules 2 | Tokenization 2 |
| i n t o n e to ne in to | i|n|t|o|n|e → |
Running tokenization locally
Now that we understand how the tokenization and the vocabulary files work, we also understand that with vocabulary files, we can do a tokenization locally. Luckily we do not have to process the files ourself (although I actually have), because we can use the NuGet package Microsoft.ML.Tokenizers and construct a tokenizer like this using the two files:
var tokenizer = new Tokenizer(new Bpe("vocab.json", "merges.txt"));
var count = tokenizer.Encode("Conveyor Conveyor Conveyor").Tokens.Count();
If I test this approach with the files from Xenovas repo, I get rather precise token count, although there are some small differences in regards to casing: If I e.g. tokenize the text The horse is running fast towards the top of the hill using the Open AI page, I get 11 tokens, where as the above approach (using the produces 12 tokens.
The difference is that the word towards is tokenized as a single token with ID 7119 by Open AI, whereas the vocabulary file produces two tokens: t|owards with the IDs 83 and 71839. The curious thing is that the token towards exists the vocabulary file with the ID 7119. Also, the following merge rule exist in the merges.txt files:
T owards
However, as the merge rules are case-sensitive, to this rule will not merge the two tokens t|owards. So, I might simply be missing a lowercase merge rule, or I am handling casing wrong. However, the token count is only a few tokens off, and always to the “positive” side, estimating a few tokens to many. So, within SitecoreSuggest you will find the vocabulary files and the Microsoft.ML.Tokenizers NuGet packages being used for counting tokens.
Tokenization in different languages
Before we wrap up, I would like to mention another issue with the tokenization and the merges.txt file which is important when using non-English languages in Sitecore. As we saw above each word is essentially split into characters, and then combined stepwise forming progressively larger clusters of characters and finally complete words if such merge rules exist.
While both the merges file and the vocabulary contain many complete words most of them English. This means that a lot of non-English words are never merged to complete words but will only have been merged into smaller bits when the merge rules have been run.
One could argue that different languages differ in the degree of inflection and use of combined words: Some languages (like English) use a lot of small words, whereas others (like Danish) uses postfixes to a single word to indicate additional grammatic “information”. E.g., the English word “horse” is in Danish “hest”, but to indicate a particular horse, in English we would say “The horse” adding the definite article “The”. In Danish we would instead add a prefix to the word itself, saying “hesten“. This is called inflection. Also, a word like “top of the hill” would in Danish be combined into a single word “bakketoppen”, and would obviously entail more tokens.
But to be honest, I think the main reason is that Open AI models are simply being trained mostly using English texts. In Danish I often see even simple word being split into 3 tokens and not necessary into the parts one would expect from a grammatical point of view (e.g., splitting out postfixes into individual tokens or splitting combined words into the grammatical parts).
Whatever the reason is, in general for non-English languages we should expect a much lower word/token ratio, even for a “large” language like French. So, for a sentence like “The horse is running fast towards the top of the hill” we have 11 words and 11 token, whereas the e.g., the French translation has 9 words and 12 tokens, and the Danish has only 5 words but 13 tokens:
| Text | Language | Words | Tokens | Word/Token |
| The horse is running fast towards the top of the hill | English | 11 | 11 | 1.00 |
| Le cheval vite vers le sommet de la colline | French | 9 | 12 | 0.75 |
| Equus currit celeriter ad summun collis | Latin | 6 | 12 | 0.50 |
| Hesten løber hurtigt imod bakketoppen | Danish | 5 | 13 | 0.38 |
Using the Microsoft.ML.Tokenizers, SitecoreSuggest will of cause recognize these differences when sending the request for different languages (the context is language specific) but the result is that if you have a multilanguage page and request a context-aware suggest, SitecoreSuggest will potentially include all English context fields when generating English suggestions, but only be able to include part of the context fields when you switch to a non-English language because the non-English context fields will simply require more tokens.
Final thoughts
When I set out to do the changes to allow SitecoreSuggest to make context-aware suggest, my main concern was how to inject the context into the ChatGPT model in a form it would “pick up”. This turned out to be surprisingly simple. On the other hand, the issue of counting tokens locally turned out to be more complex than I imagined – mainly because I did not just want to include the vocabulary files without knowing that they did.
So while this post turned out like it did, I hope you found this explanation of the tokenization process interesting because although I simply wanted to restrict the amount to tokens sent, understanding the tokenization does in fact offers to insights into the inner workings of the GPT model’s vocabulary.